Searching in JBrowse 2 is quite similar to searching in JBrowse 1. The most common way you would look for a feature would be to type the name of a feature in the location field (that is, the field that has the current location in it, like this:
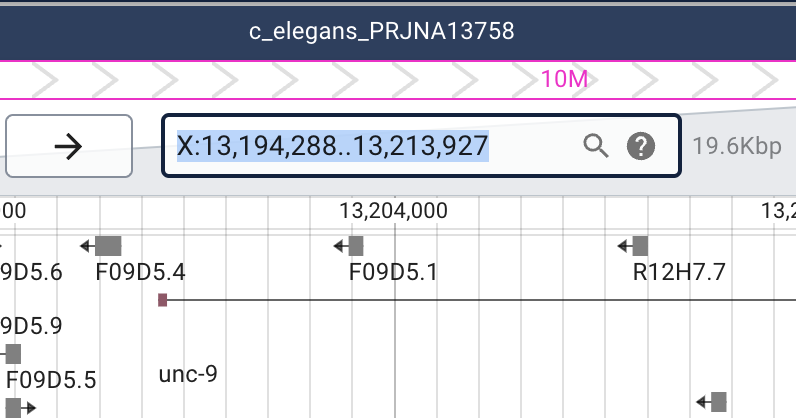
Anything that you could search for in JBrowse 1 you can search for in JBrowse 2, and there is a good reason for that: they are using exactly the same data and search indexes. So, you can look for gene and transcript names, identifiers like WBGene00006749, and allele names like pkP649. Of course, you can also enter a location like II:100000..200000. The only difference in name searching between JBrowse 1 and 2 is that when you search for something, you will almost always get a message like this in the bottom of the screen:
[Read more…]





